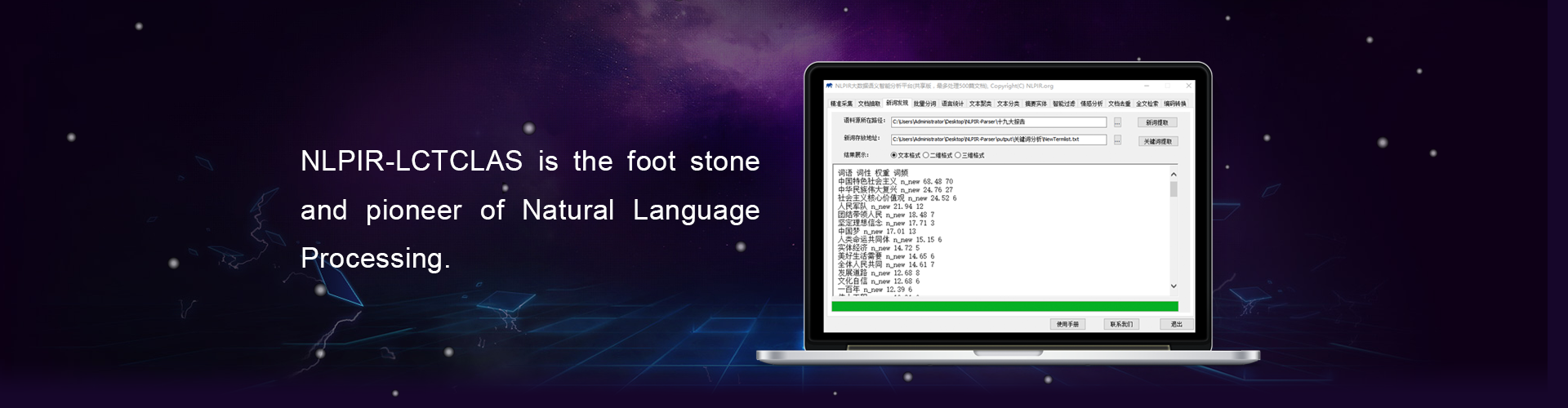
The NLPIR system is multi-functional that supports Chinese word segmentation, English tokenization, Part-Of-Speech (POS) tagging, named entity recognition, new word identification, keywords extraction, and user-defined lexicon.
Automatic tokenization and POS tagging for both Chinese and English

Use information entropy algorithm to extract keywords for both recorded and unrecorded words.
Identify the new words using information entropy from a given untagged corpus.Add the extracted new words to the language model to analyze the high-frequency words and reach the adaptive segmentation.

Import the self-defined words into NLPIR system one by one or in bulk, refining the segmentation results with a real-time speed.